.png?width=900&height=186&name=Advantco%20logo%20AAC%20V1%20Ai%20file%201%20(1).png "Advantco logo AAC V1 Ai file 1 (1)")

.png)
.png)











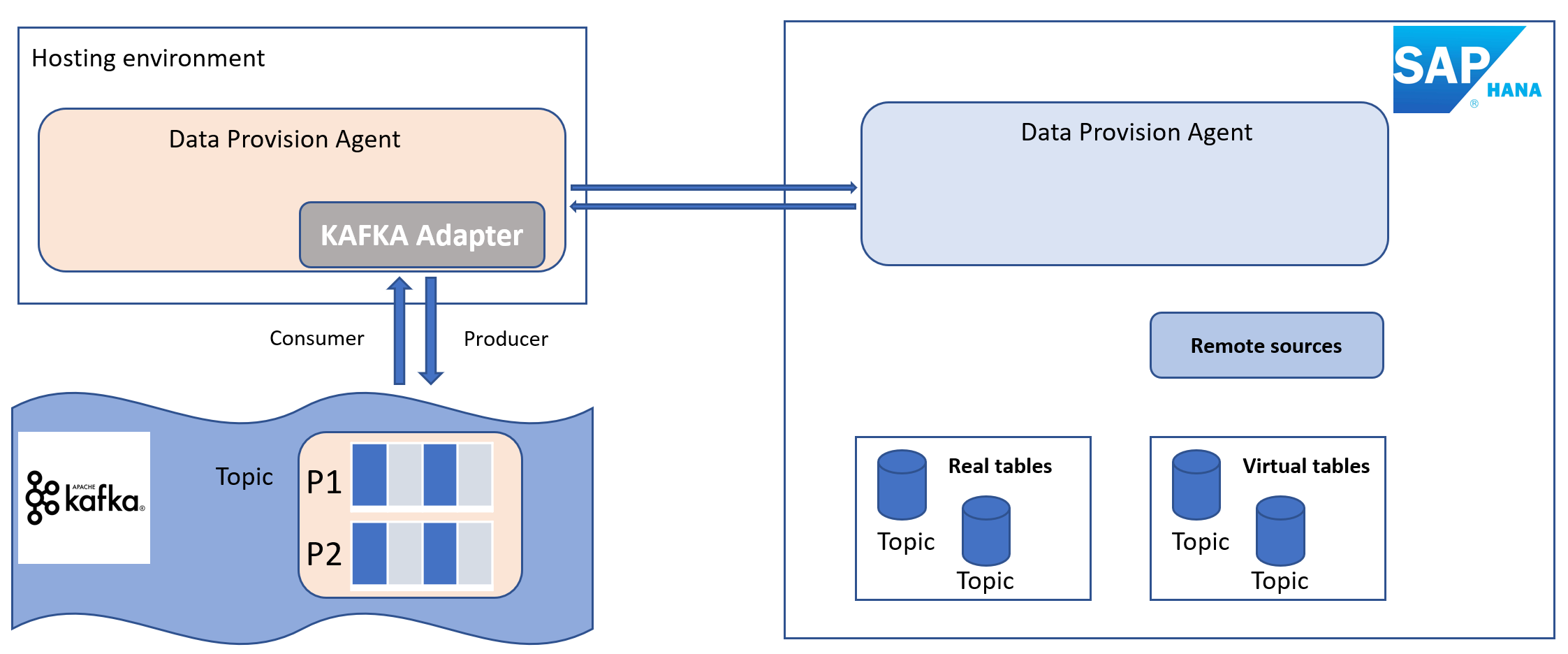
SAP HANA smart data integration and SAP HANA smart data quality load data, in batch or real-time, into HANA (on premise or in the cloud) from a variety of sources using pre-built and custom adapters. The Kafka adapter is an example of a custom adapter made available by Advantco.
Apache Kafka is an open-source distributed event streaming platform for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
In this blog, we discuss a solution to consume data from a KAFKA topic and to publish data to a KAFKA topic.
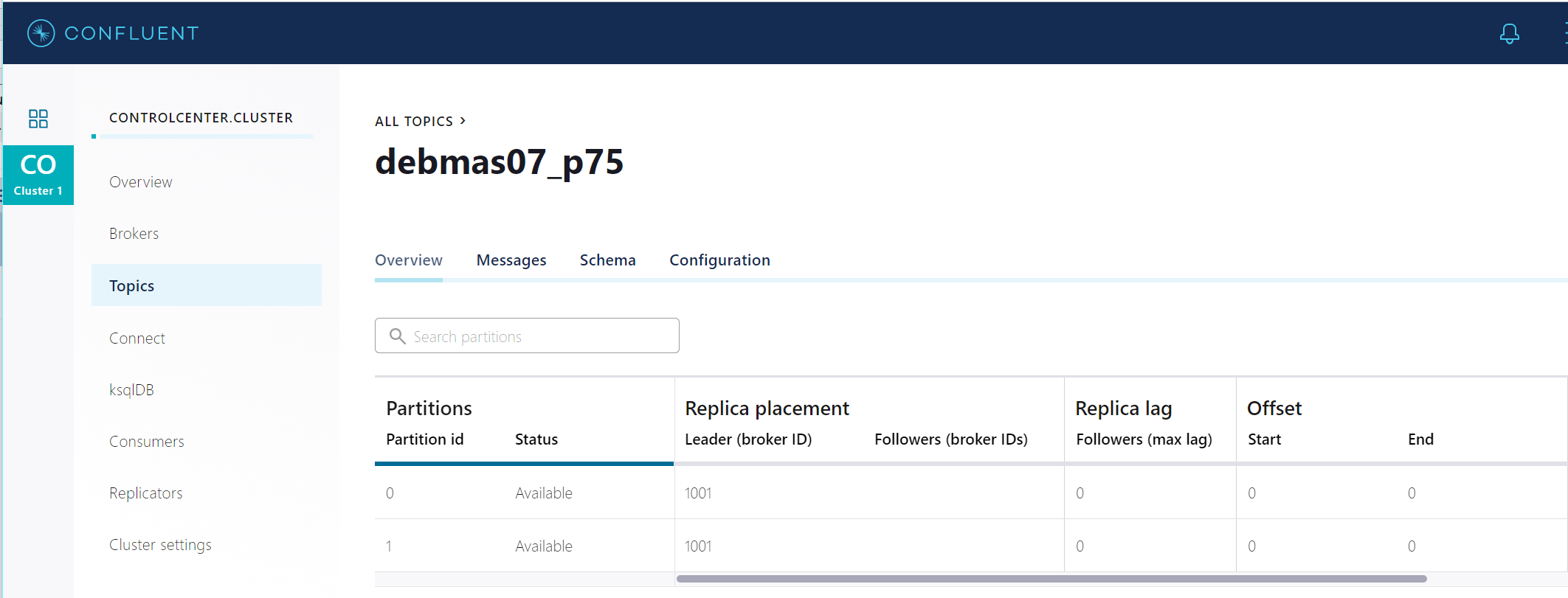
KAFKA topic setup
We create a topic on the KAFKA broker with two partitions. We publish a simplified DEBMAS to this topic. This topic has two partitions.
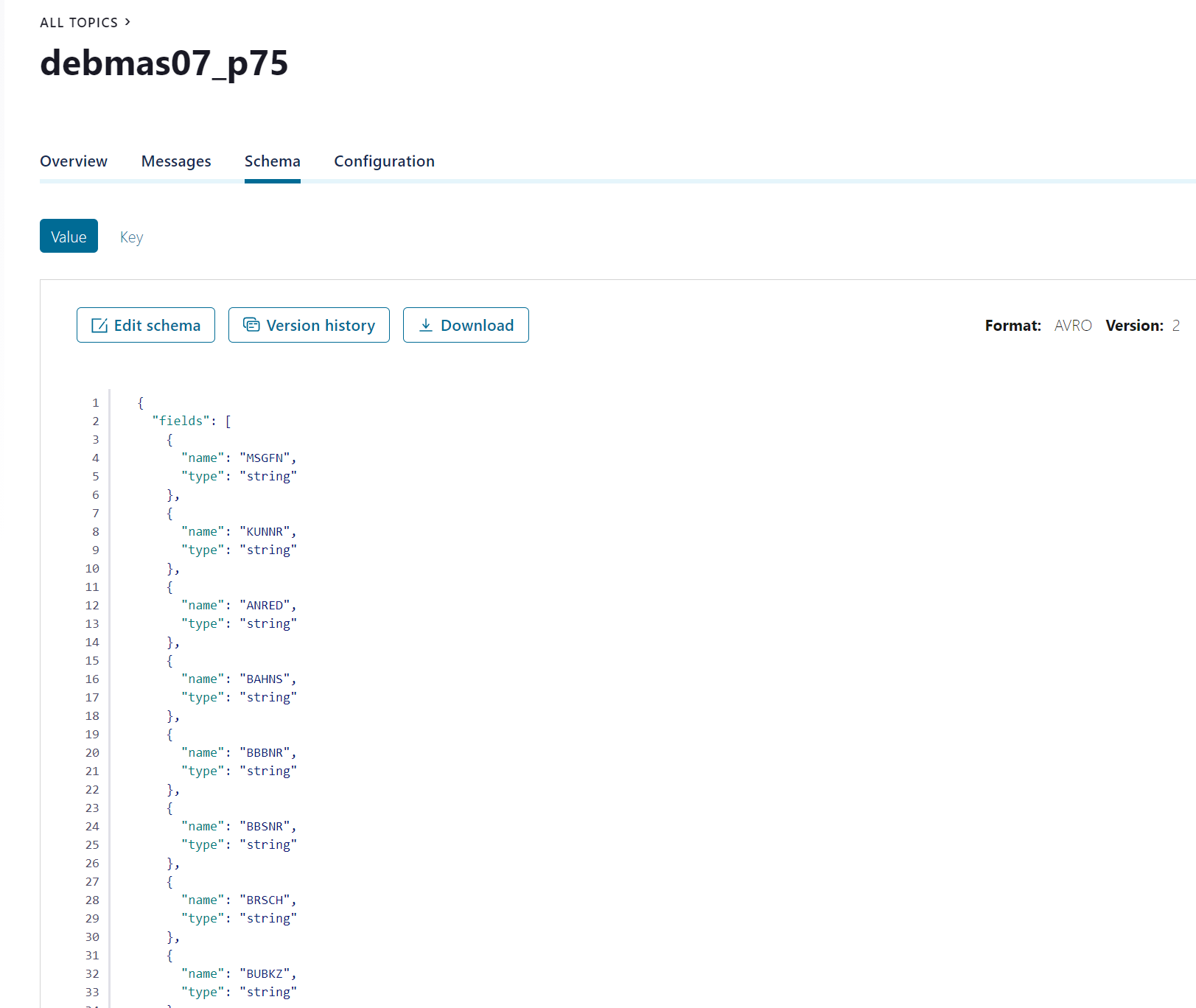
An Avro schema, defining the structure of the data, is associated for the topic value. This schema will define the table schema in HANA.
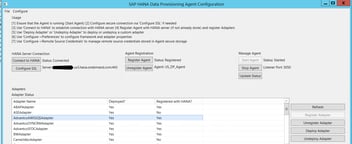
The Kafka adapter installation.
The Kafka adapter is deployed in the hosting environment where the Provision Agent was installed. After the deployment, we register the Kafka adapter to the HANA server which can be on premise or in the cloud. Note that each agent has an Agent Name.
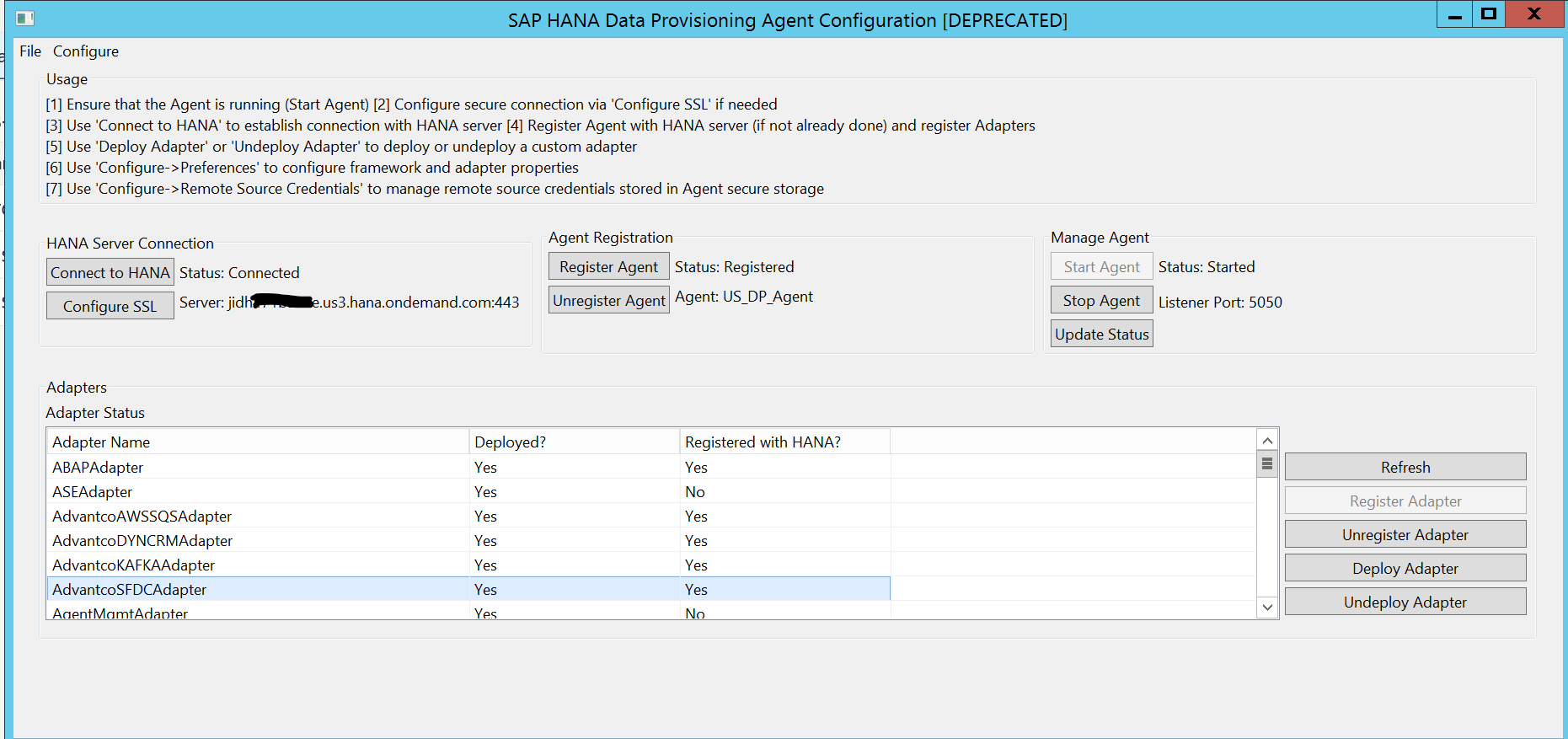
HANA Development Workbench.
In this blog, we use the HANA Cloud instance. We use the HANA Workbench to define the connection to KAFKA broker by creating a Remote Source. We will also use the Workbench to create a replication task to consume data from a KAFKA topic into a real HANA table.

KAFKA Remote Source.
The Remote Source uses the registered KAFKA adapter that we deployed on the Provision Agent to create a connection to the KAFKA broker. To create the Remote Source, select the KAFKA adapter and the Agent Name. Specify the KAFKA broker hosts and ports, configure the parameters and do the connection test.
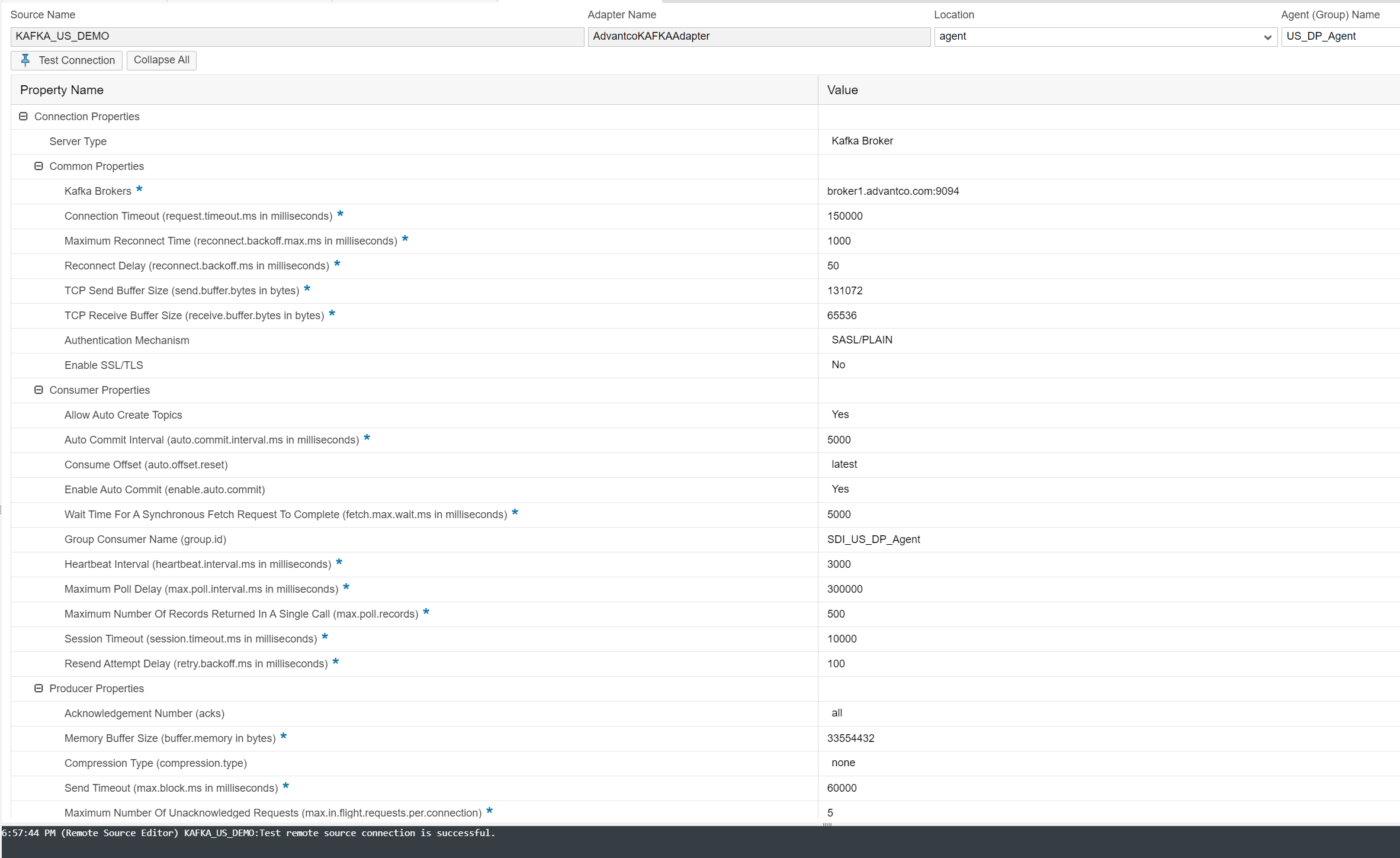
Virtual Table
Once the Remote Source is created, you should see the topics that were defined on the KAFKA broker. You can create a Virtual Table by right-clicking on a topic.
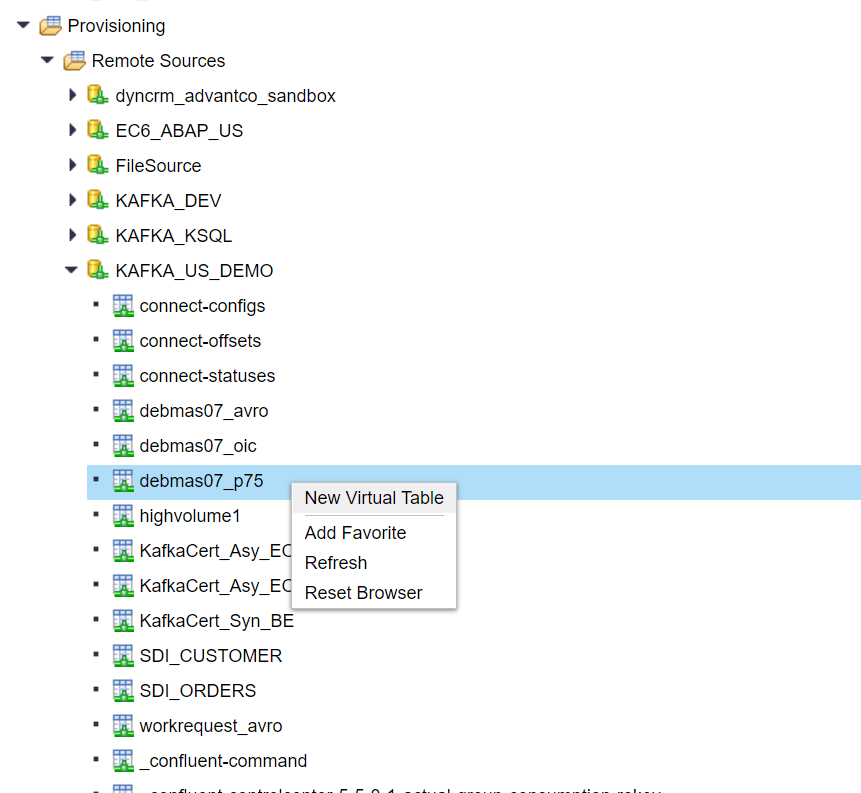
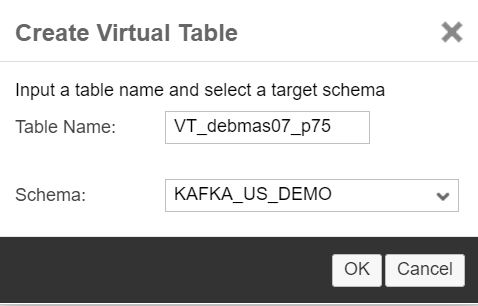
The Virtual Table schema is based on the Avro schema defined for the topic on the KAFKA broker side.
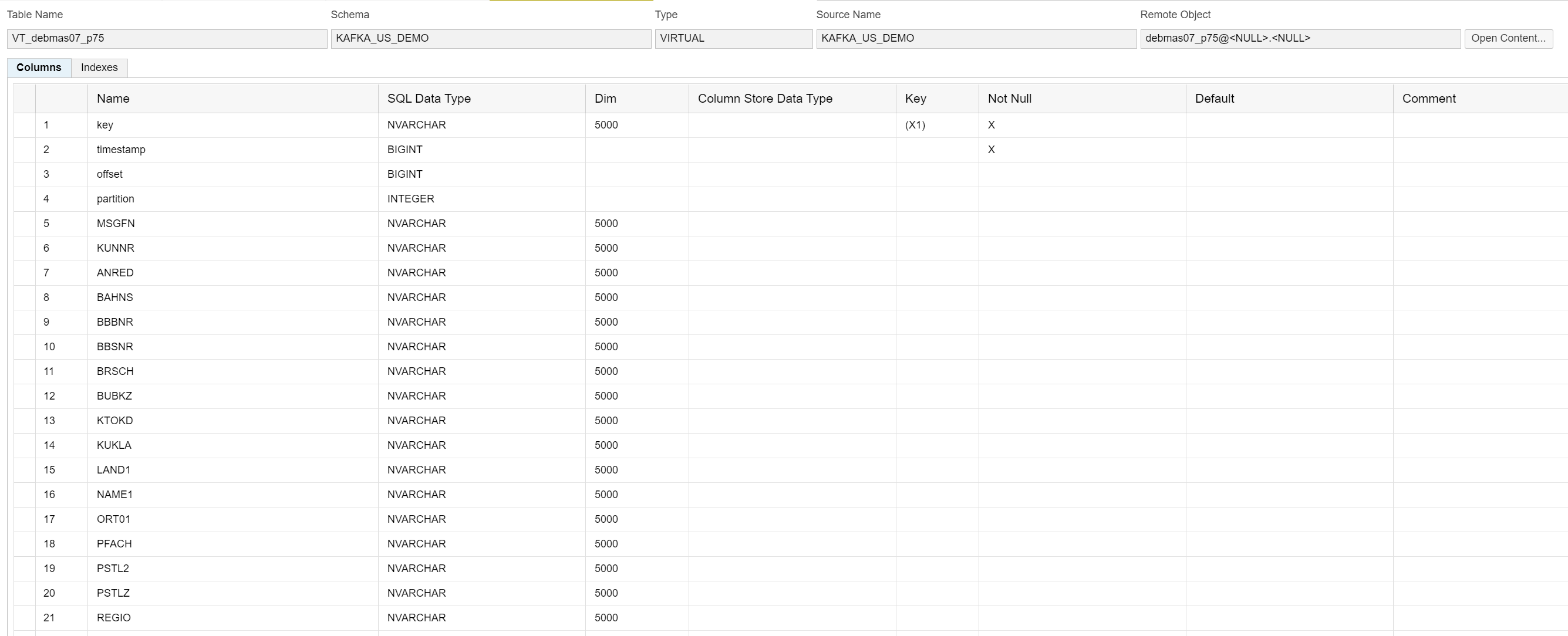
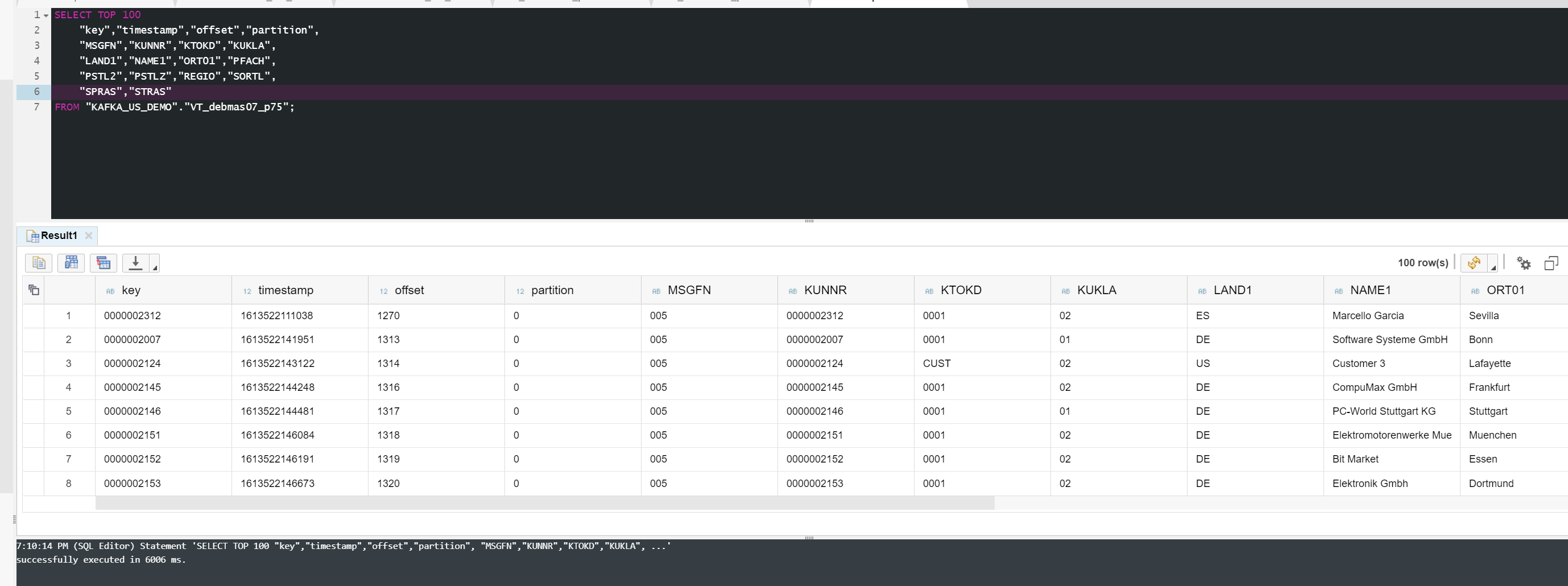
The Virtual Table is a direct connection to a topic, when querying the Virtual Table, you act like a KAFKA consumer. When inserting into the Virtual Table, you act like a producer.
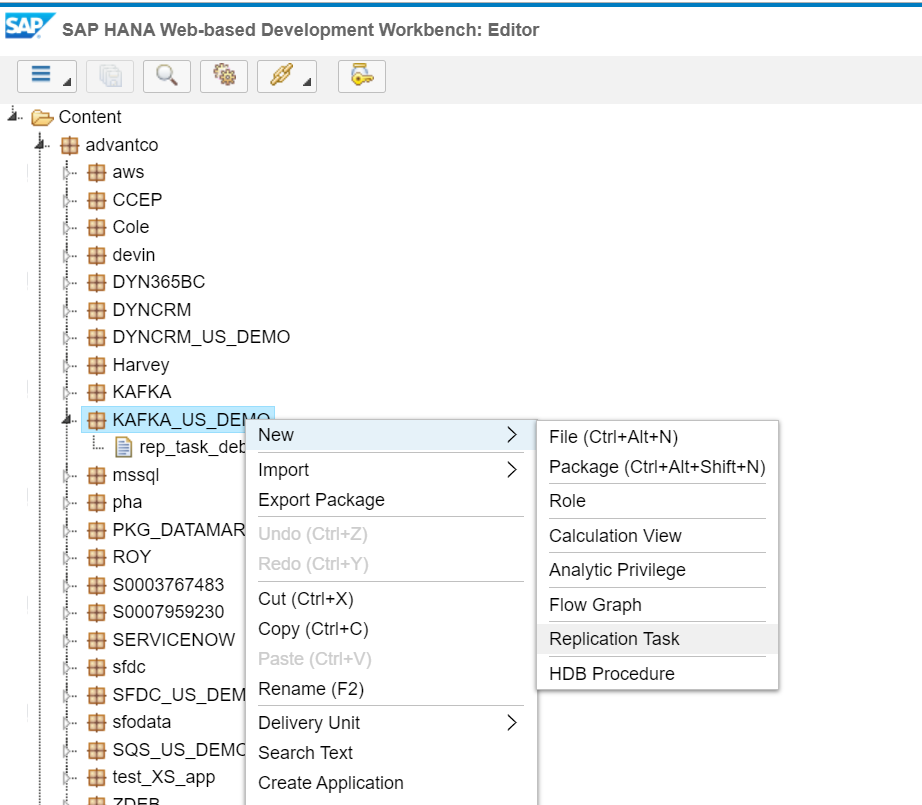
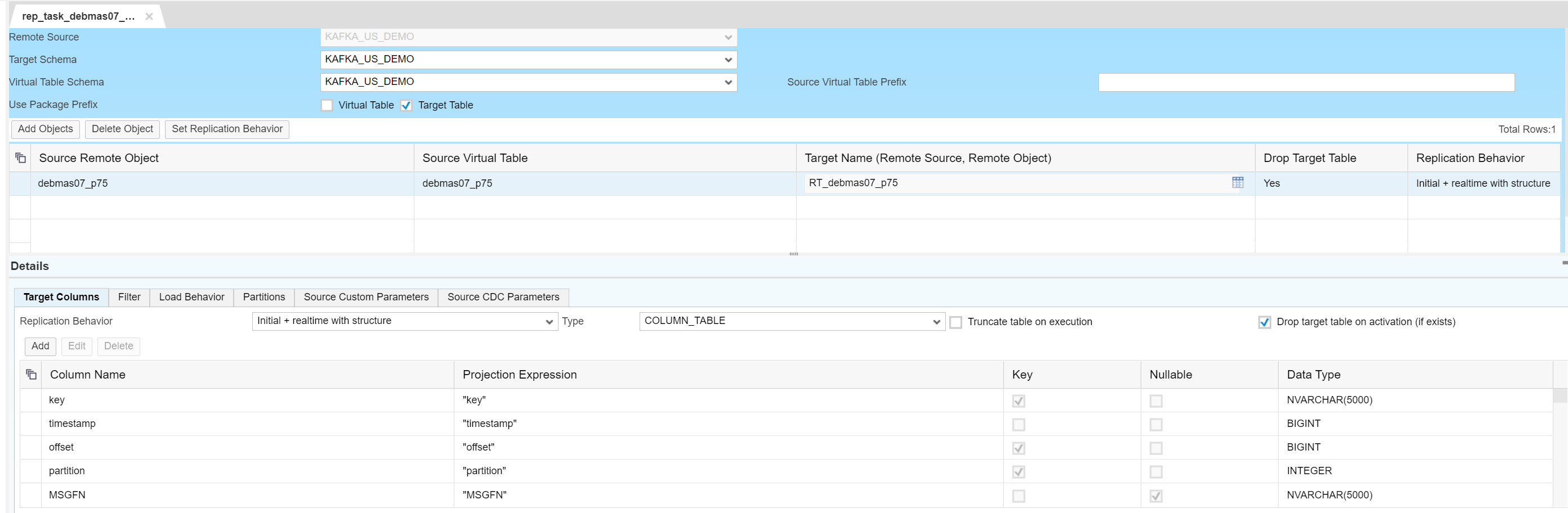
Replication Task
In this step, we will create a task to replicate data from the KAFKA topic into a Real Table in HANA. This is done in the Editor section of the HANA workbench.
We select the Remote Source we defined above, specify the Target Schema and click on Add Objects to choose one or more topics that we want to replicate.
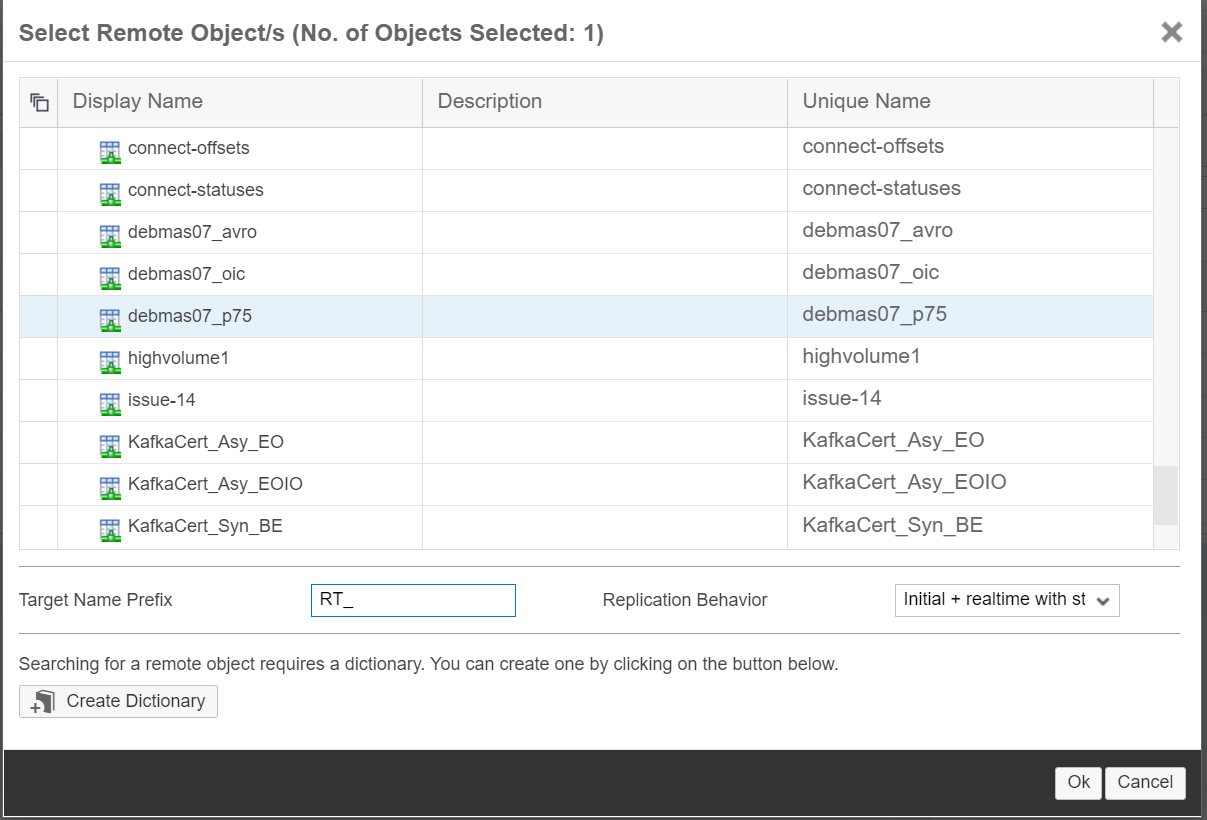
Once the topic is added, you can edit the column properties if needed.
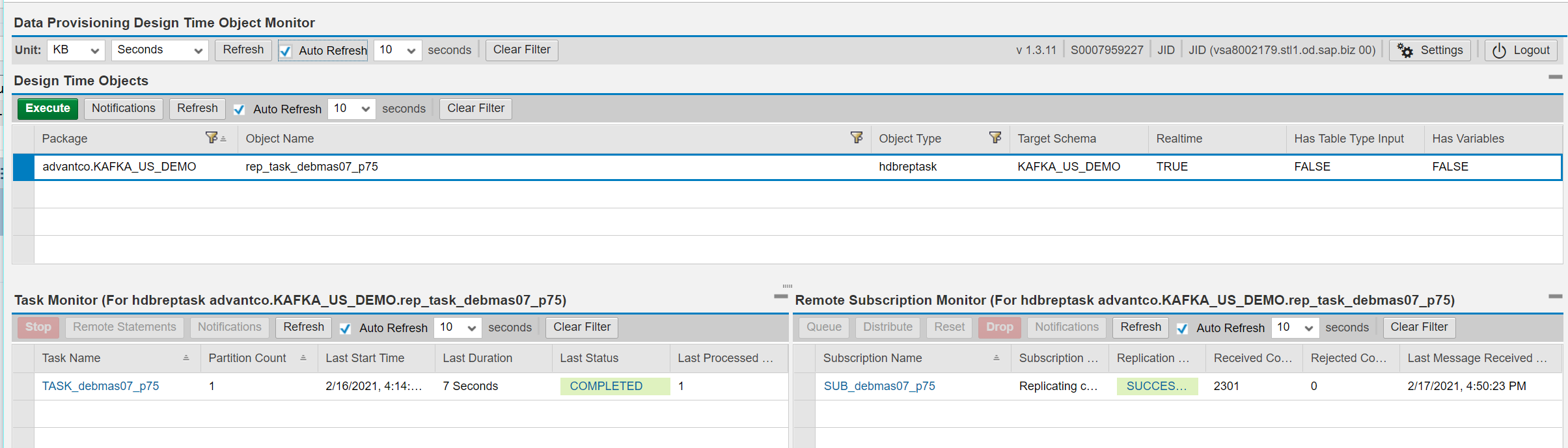
Executing the task to start the replication task. You can monitor the progress with the Data Provisioning Design Time Object Monitor.
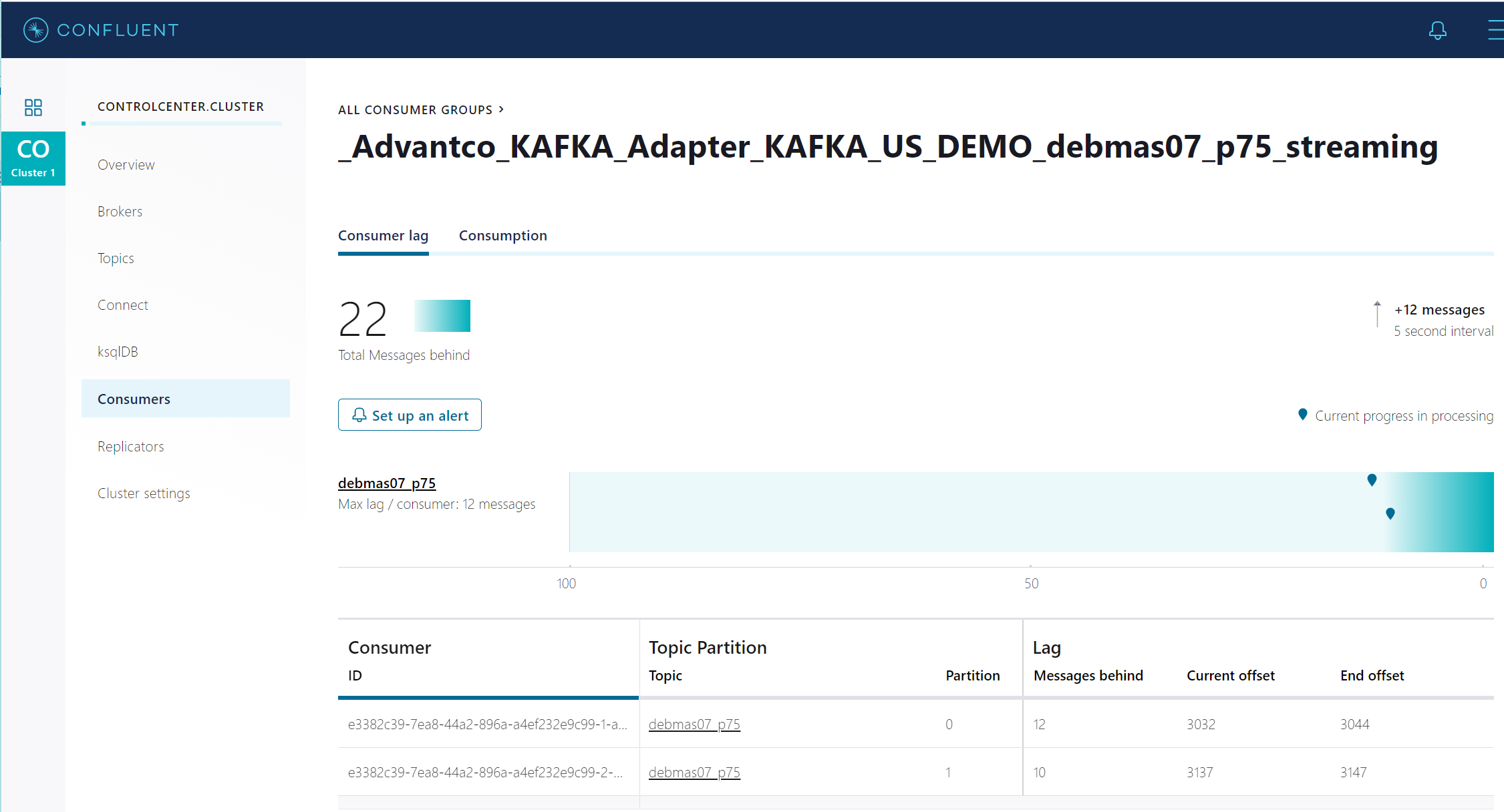
On the KAFKA broker side, you can see that the messages are being consumed.
Conclusion
The KAFKA adapter for SAP HANA SDI (Smart Data Integration) provides a very convenient way to replicate data from a KAFKA topic to a HANA table. The KAFKA adapter also supports publishing data from HANA to a KAFKA broker.
Sources:
https://help.sap.com/viewer/product/HANA_SMART_DATA_INTEGRATION/2.0_SPS05/en-US?task=discover_task
Please reach out to our sales team at sales@advantco.com if you have any questions.